 Login as
Login asBy Arun Mani – Web Analytics Master
This is the first of a series of posts on the tool Screaming Frog SEO spider. This free tool allows you to quickly determine things you need change on your website which will help with your site’s SEO ranking.
Go to the website www.screamingfrog.co.uk . Download the free version of the software and install it on your PC.
When you first bring up Screaming Frog, on the main screen, at the top, you will see a text box to enter a URL. Enter the URL, the click the ‘Start’ button to start crawling your site.

Top of main screen
In this article we will look primarily at ‘Directives’ such as Canonical, Index, Noindex, etc.
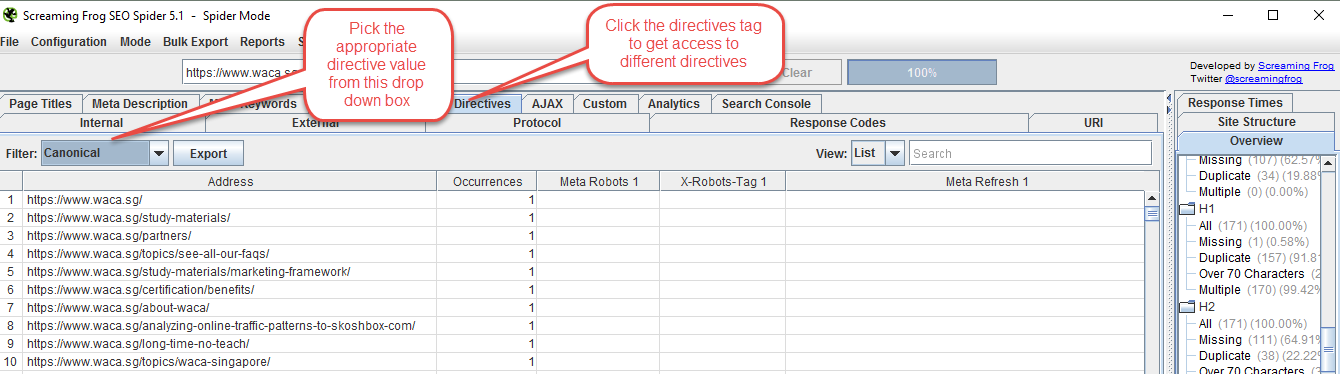
Screaming Frog directives
Picking the ‘Canonical’ value from the dropdown box will show you all pages on your website that are tagged as being a canonical version of a URL.
What is the canonical tag? If you have two or more pages on your website with exactly the same content, but each of these pages have a different URL, how does Google determine which of these pages should have it’s link and content metrics included in determining the search rank of the page? Use the rel=canonical tag.
Example: you have four pages A, B, C, D with duplicate content but different URLs. You want to specify to Google Bot that page A with URL http://www.waca.associates/canonical-version-of-page is the page to be used for SEO purposes. You will insert the following HTML code in the HTML head of the pages B, C, D:
<link href="http://www.waca.associates/canonical-version-of-page/" rel="canonical" />
This tells Google the page that contains this rel=canonical tag is a copy of http://www.waca.associates/canonical-version-of-page/ and all link and content metrics should be credited to the provided URL http://www.waca.associates/canonical-version-of-page/ .
The next directive we will discuss is the noindex directive. This directive is a meta tag and applies to the whole page:
<meta name=”googlebot” content=”noindex”> is placed in the header section of an HTML page.
This particular page is then not crawled by Google Bot as it crawls the entire website.
The syntax varies based on the search engine. For Yahoo for example it is:
<meta name=”slurp” content=”noindex”>
The nofollow directive is a value that can be assigned to the rel attribute of an HTML a element.
Example:
<a href=”http://www.waca.associates/a/” rel=”nofollow”>:
This will instruct search engines that the hyperlink should not influence the ranking of the link’s target “http://www.waca.associates/a/” in the search engine’s index.
Using Screaming frog allows you to identify missing canonical tags, incorrect canonical tags, pages that should not be indexed but have the tag “index” associated with it and many other problems related to directives. I will cover Screaming frog in a little more detail in future posts.































;>/img/banner/partner $url=>$index; .png)